Formation
TP Docker (3) – Un conteneur CMatrix pour toutes les plateformes
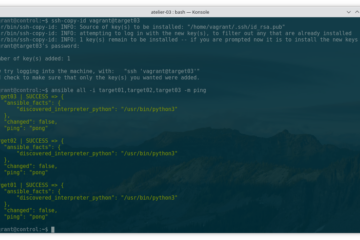
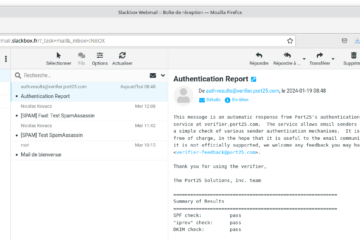
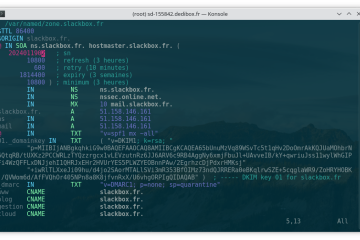
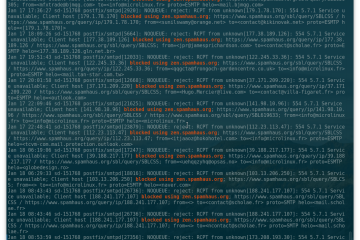
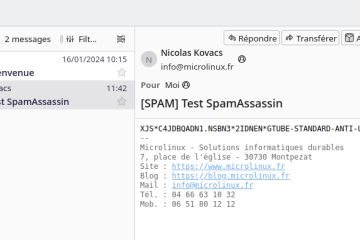
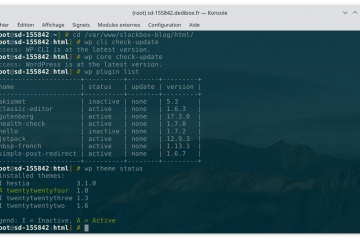
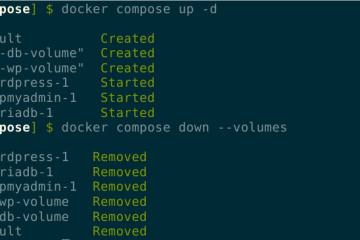
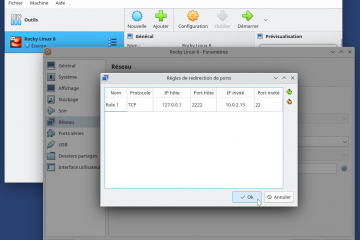
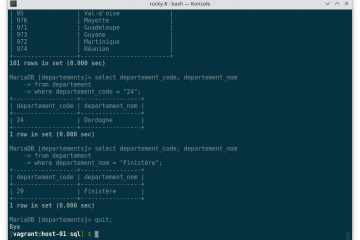
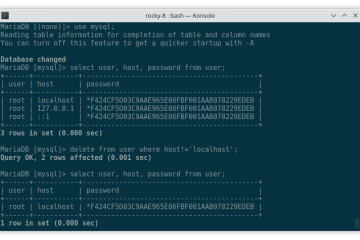
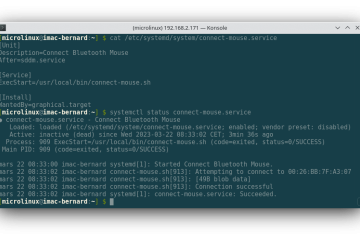
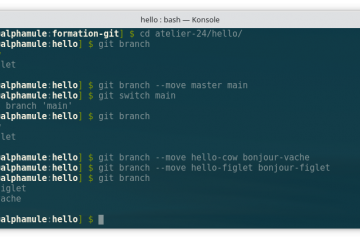
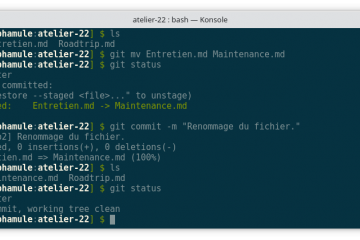
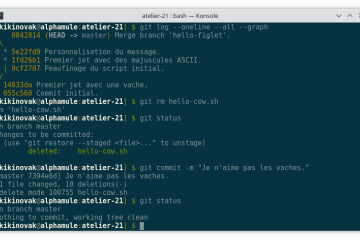
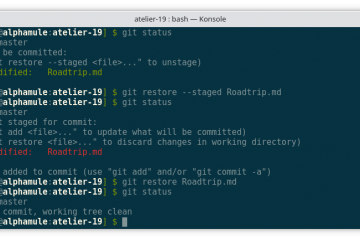
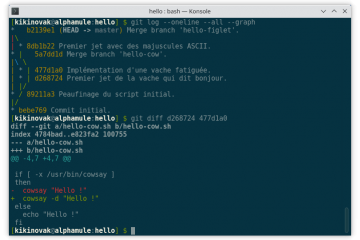
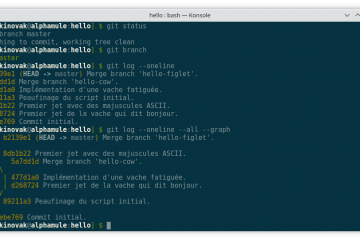
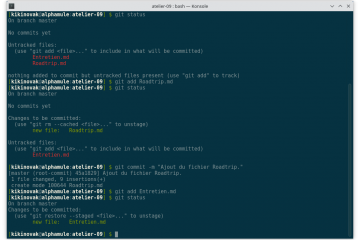
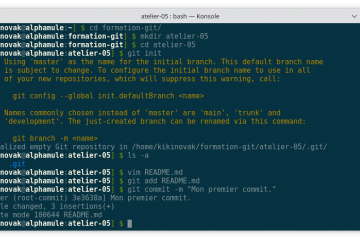
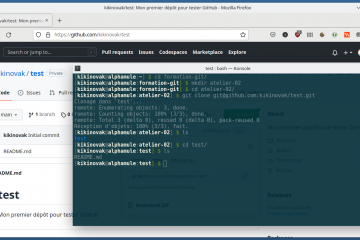
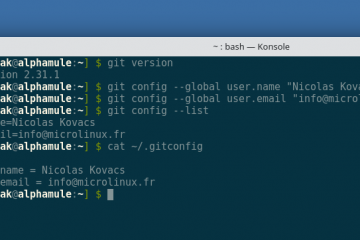
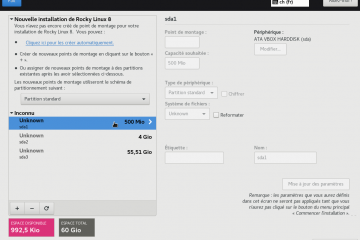
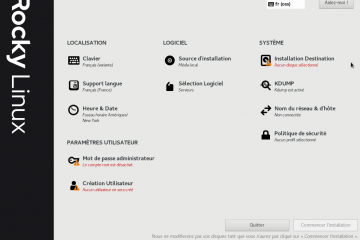
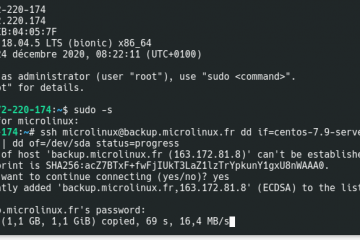
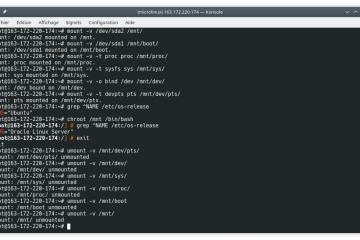
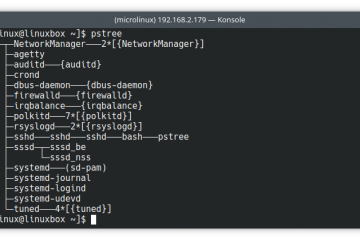
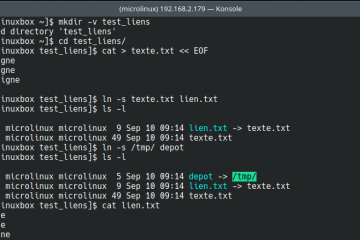
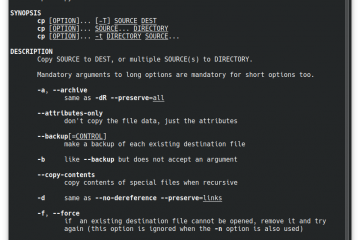
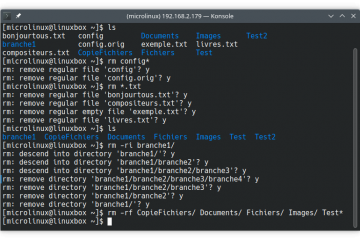
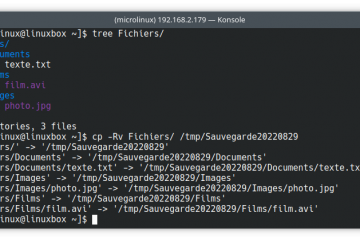
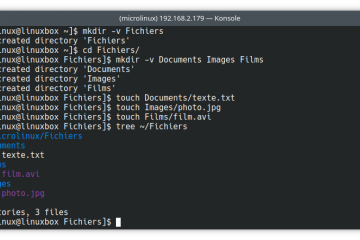
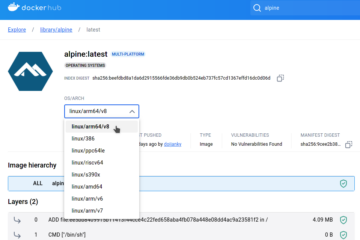
Voici la troisième et dernière partie du TP Docker dans le cadre de la formation Docker. Dans mon précédent article nous avons construit une image de conteneur optimisée de l’économiseur d’écran CMatrix basée sur Alpine Lire la suite…