Formation
Git par la pratique (28) – Aider un collègue
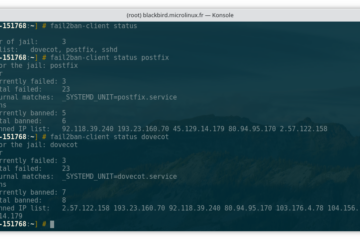
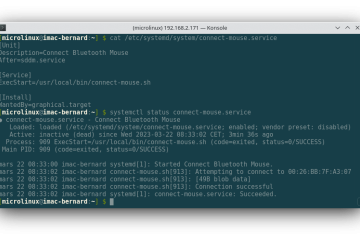
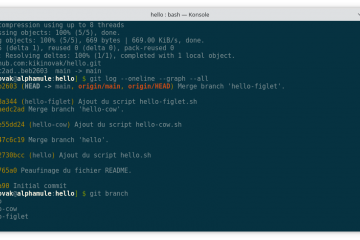
Voici le vingt-huitième volet de la formation Git. Dans mon précédent article, nous avons vu comment nous pouvons récupérer la travail effectué par un collègue sur sa propre branche. Cette manipulation nous permet de faire Lire la suite…