![]() Voici le cinquième article consacré au serveur de supervision Icinga. Dans notre précédent article, nous avons défini une collection de tests fondamentaux qui permettent de garder un œil sur l’état de santé de notre machine. Reste à savoir ce que nous sommes censés faire en cas d’anomalie.
Voici le cinquième article consacré au serveur de supervision Icinga. Dans notre précédent article, nous avons défini une collection de tests fondamentaux qui permettent de garder un œil sur l’état de santé de notre machine. Reste à savoir ce que nous sommes censés faire en cas d’anomalie.
En effet, vous n’allez probablement pas rester les yeux rivés sur le tableau de bord d’Icinga pour superviser votre parc de machines – à moins que vous ne soyez un grand opérateur avec votre propre datacenter et des gens payés pour faire ça à longueur de journée.
Si votre entreprise est de taille plus modeste, la solution la plus pragmatique consiste à activer les notifications par mail en cas de problème. C’est relativement simple à mettre en œuvre.
Prérequis
Icinga doit pouvoir envoyer des notifications. Votre serveur de supervision doit donc être doté d’une installation minimale de Postfix capable d’envoyer des e-mails.
Activer les notifications
Ouvrez le fichier de configuration d’un de vos hôtes, repérez la stance object Host et ajoutez trois lignes comme ceci :
// /etc/icinga2/zones.d/master/host-sd-151768.dedibox.fr.conf object Endpoint "sd-151768.dedibox.fr" { } object Zone "sd-151768.dedibox.fr" { endpoints = [ "sd-151768.dedibox.fr" ] parent = "master" } object Host "sd-151768.dedibox.fr" { import "generic-host" address = "163.172.81.8" vars.os = "Linux" vars.client_endpoint = name vars.notification["mail"] = { groups = [ "icingaadmins" ] } }
Enregistrez les modifications, ouvrez le fichier conf.d/users.conf et renseignez l’adresse mail vers laquelle vous souhaitez envoyer les notifications :
// /etc/icinga2/conf.d/users.conf object User "icingaadmin" { import "generic-user" display_name = "Icinga Admin" groups = [ "icingaadmins" ] email = "info@microlinux.fr" } object UserGroup "icingaadmins" { display_name = "Icinga Admin Group" }
 Oui, c’est mieux si vous mettez votre adresse mail. Non, ce n’est pas une bonne idée de mettre la mienne. Je dis ça parce que je reçois régulièrement des notifications en provenance de machines configurées par des lecteurs qui prennent mes articles un peu trop au pied de la lettre.
Oui, c’est mieux si vous mettez votre adresse mail. Non, ce n’est pas une bonne idée de mettre la mienne. Je dis ça parce que je reçois régulièrement des notifications en provenance de machines configurées par des lecteurs qui prennent mes articles un peu trop au pied de la lettre.
Vérifiez la syntaxe de votre configuration et prenez en compte les modifications :
# icinga2 daemon -C # systemctl reload icinga2
Simuler un dysfonctionnement
Pour tester le bon fonctionnement de ma configuration, je vais simuler un dysfonctionnement sur la serveur dédié que je surveille.
Ma partition /boot est relativement réduite, et elle est utilisée à un peu plus de la moitié :
# df -h /boot Filesystem Size Used Avail Use% Mounted on /dev/sda1 488M 246M 206M 55% /boot
Je vais la remplir à ras bord en créant un fichier « bidon » rempli de zéros :
# dd if=/dev/zero of=/boot/0bits bs=1M count=200 200+0 records in 200+0 records out 209715200 bytes (210 MB, 200 MiB) copied, 0.490476 s, 428 MB/s
Voyons le résultat de l’opération :
# df -h /boot Filesystem Size Used Avail Use% Mounted on /dev/sda1 488M 446M 5.6M 99% /boot
Je jette un œil sur le tableau de bord d’Icinga, et le problème me saute aux yeux :
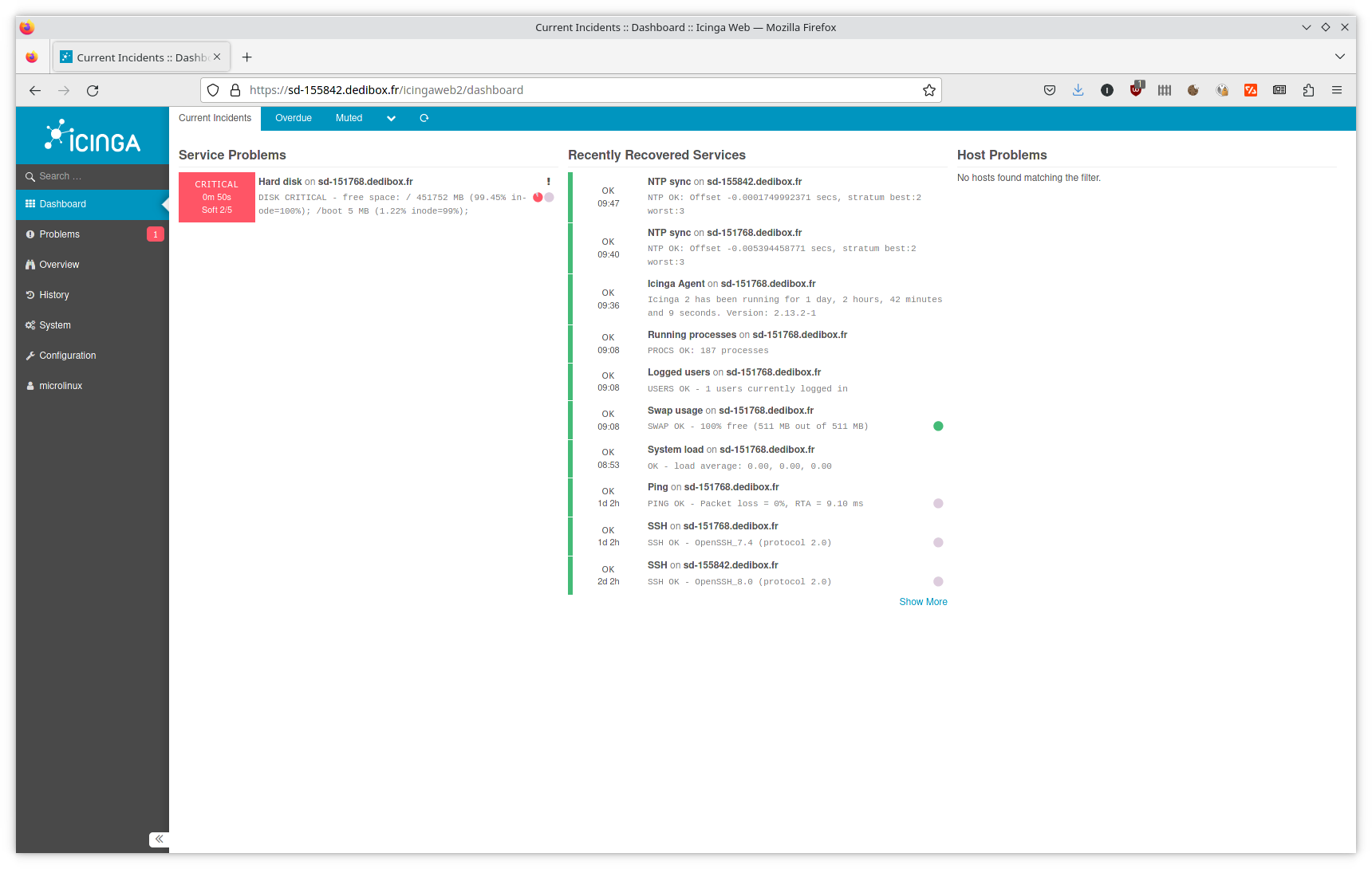
À partir du moment où Icinga détecte un composant ou un service dans un état critique – ou lorsqu’il n’arrive plus à joindre un hôte distant – il vous envoie une notification. Je jette un œil dans ma messagerie, et effectivement :
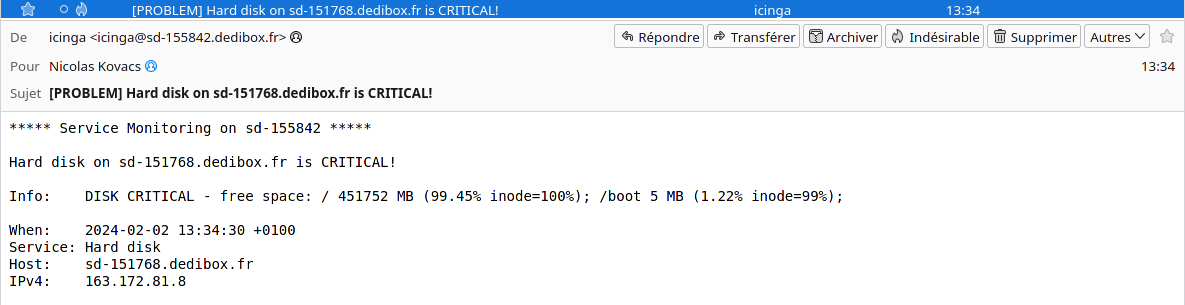
Je me connecte donc à la machine en question, j’identifie le problème et j’essaie de le résoudre. En l’occurrence c’est très simple, puisque c’est moi qui l’ai créé à la base :
# rm -f /boot/0bits
Je vérifie sur le tableau de bord, et je vois que tout est rentré dans l’ordre. Mais je n’ai même pas besoin de faire ça, puisque mon serveur de supervision fait bien les choses. En effet, il m’envoie une deuxième notification pour m’indiquer que les choses sont retournées à la normale :
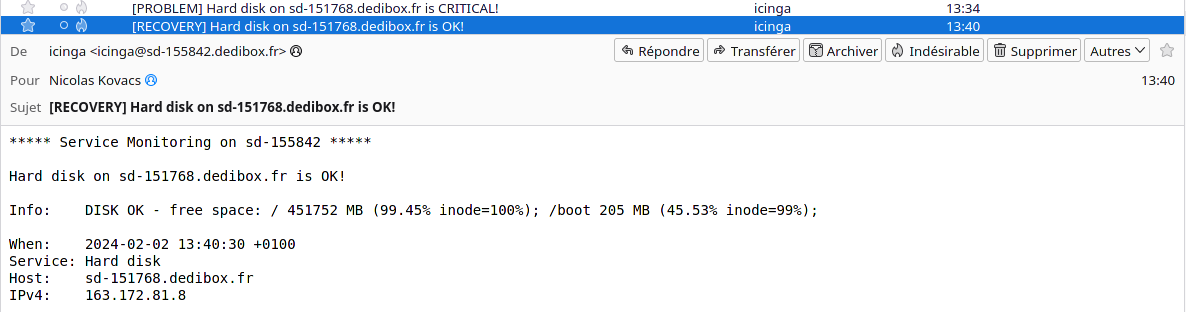
La suite au prochain numéro, où nous allons essayer de connecter un serveur derrière un NAT.
La rédaction de cette documentation demande du temps et des quantités significatives de café espresso. Vous appréciez ce blog ? Offrez un café au rédacteur en cliquant sur la tasse.

0 commentaire